A simplified minimodel of visual cortical neurons
Simplified and interpretable “minimodels” are sufficient to explain complex visual responses in mouse and monkey V1.
Abstract
Artificial neural networks (ANNs) have been shown to predict neural responses in primary visual cortex (V1) better than classical models. However, this performance often comes at the expense of simplicity and interpretability. Here we introduce a new class of simplified ANN models that can predict over 70% of the response variance of V1 neurons. To achieve this high performance, we first recorded a new dataset of over 29,000 neurons responding to up to 65,000 natural image presentations in mouse V1. We found that ANN models required only two convolutional layers for good performance, with a relatively small first layer. We further found that we could make the second layer small without loss of performance, by fitting individual “minimodels” to each neuron. Similar simplifications applied for models of monkey V1 neurons. We show that the minimodels can be used to gain insight into how stimulus invariance arises in biological neurons.
Thread by Fengtong Du:
- Predicting neural activity is notoriously difficult and requires complicated models. Here we develop simple “minimodels” which explain 70% of neural variance in V1! 🐭🐒

- We started with population-level models, fitting all neurons together with 4 shared conv layers. These models performed better than past models because we showed many more images. The model predicted monkey V1 responses well too.
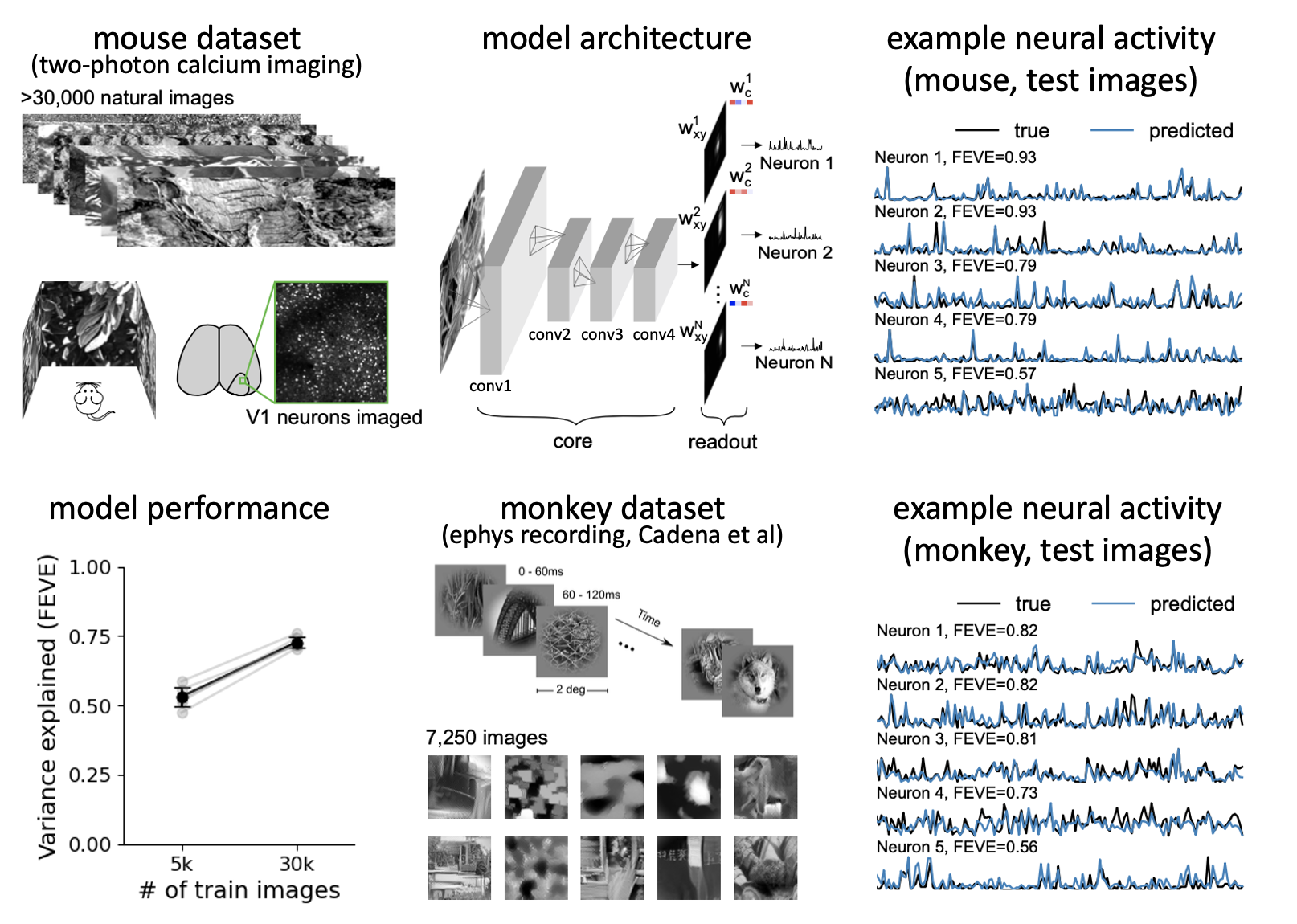
- But we didn’t need such a deep network: two convolutional layers were sufficient, in both mice and monkeys. Also, the first layer could be very small, 16 filters, while the second layer did need to be large, in line with the high dimensionality of V1.
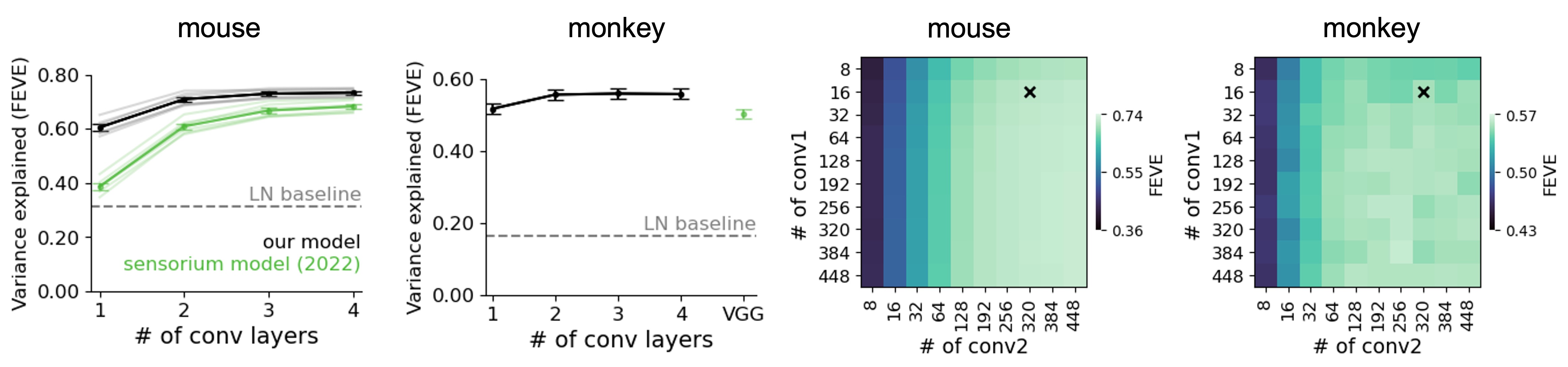
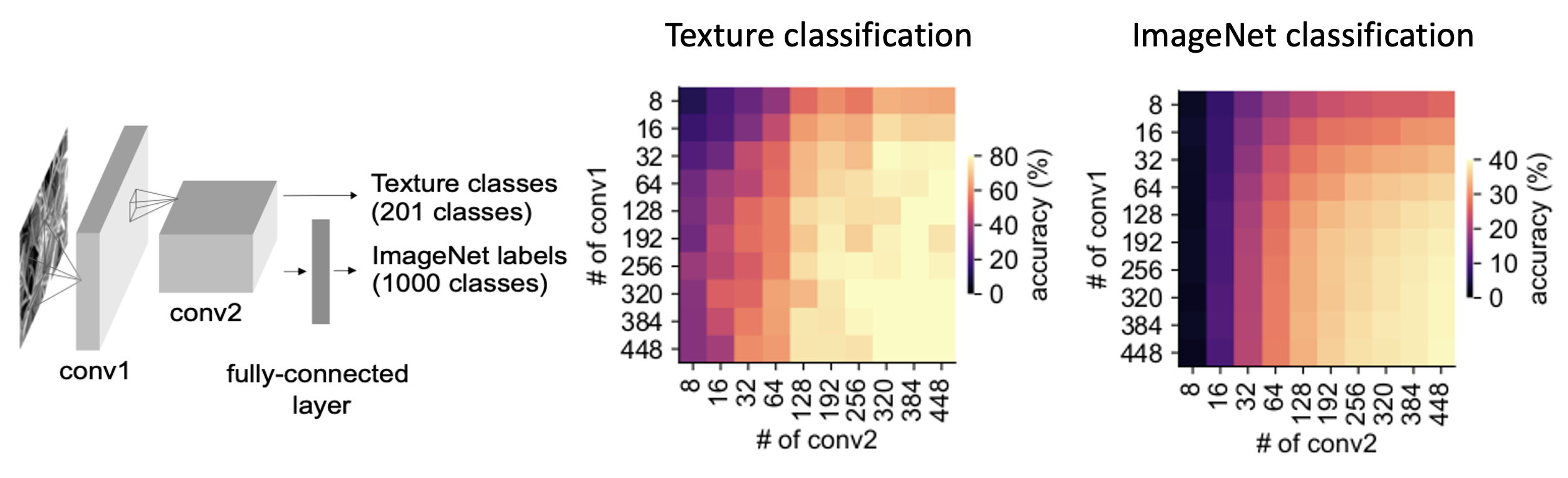
- This structure – small first convolutional layer and large second convolutional layer – was advantageous for performing visual tasks, such as texture classification and image recognition.
- Next, can we simplify the wide second layer further? We found that using more neurons to fit the model did NOT help! This suggested that we could fit smaller models to individual neurons.
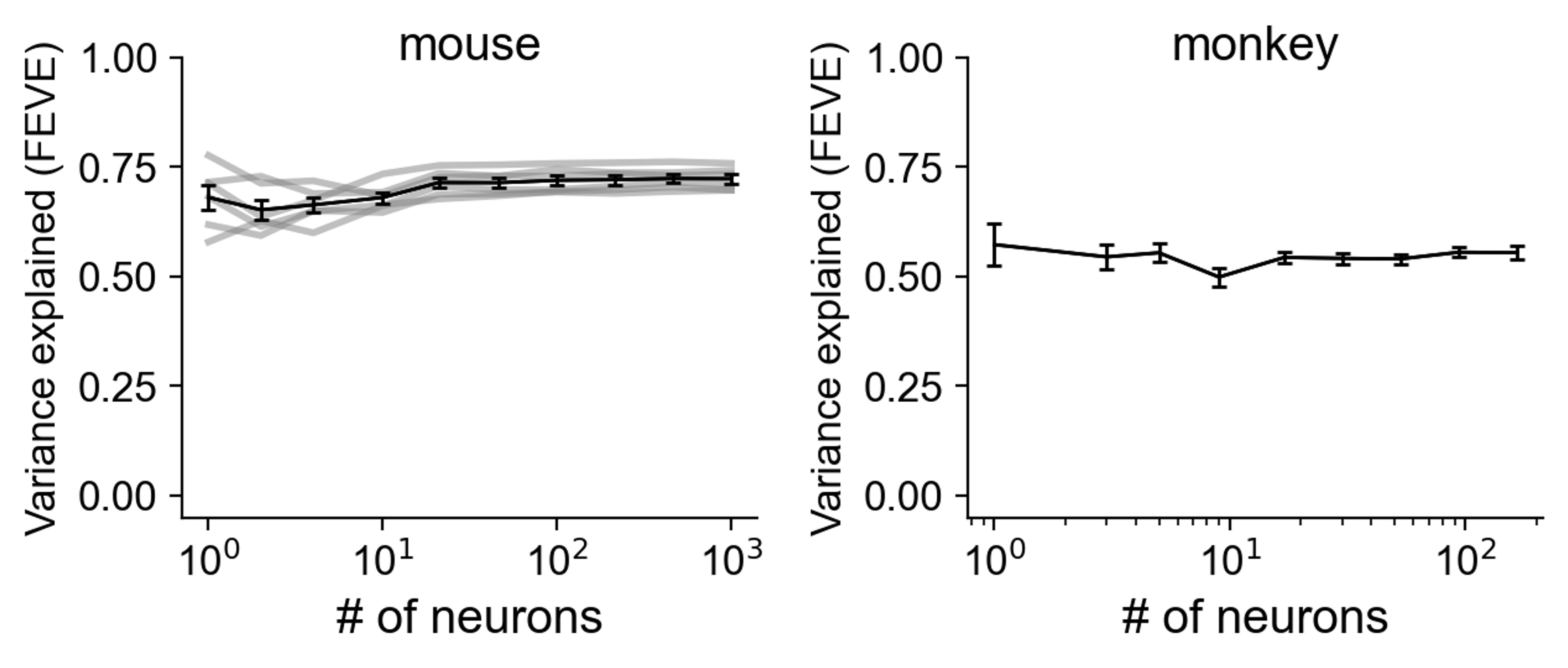
- So we built a minimodel for each neuron, matching the performance of the best models. On average, mouse minimodels had 32 conv2 filters and monkey minimodels had 7, much fewer than the 320 filters in our previous model.
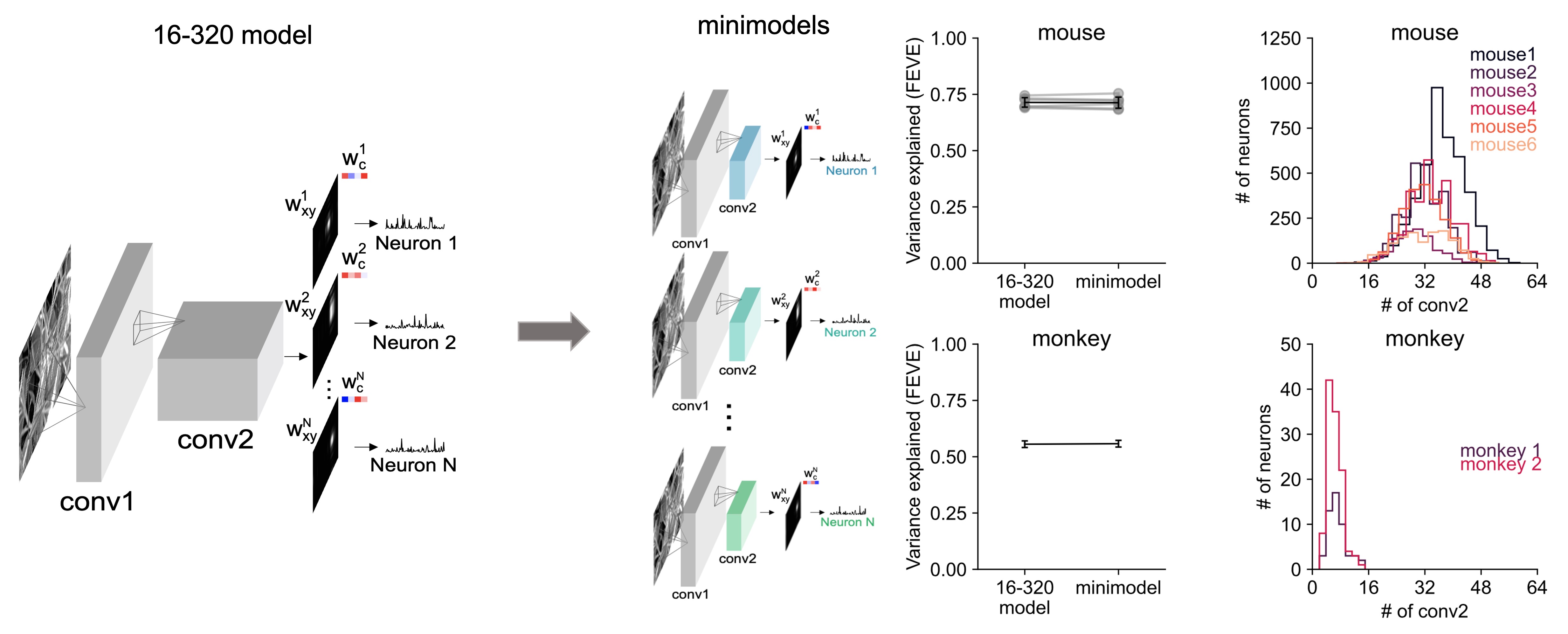
- Now equipped with a minimodel for each neuron, we used them to understand how the visual invariance of a single neuron develops across the model stages. We designed a metric, fraction of category variance (FECV) to measure this invariance.
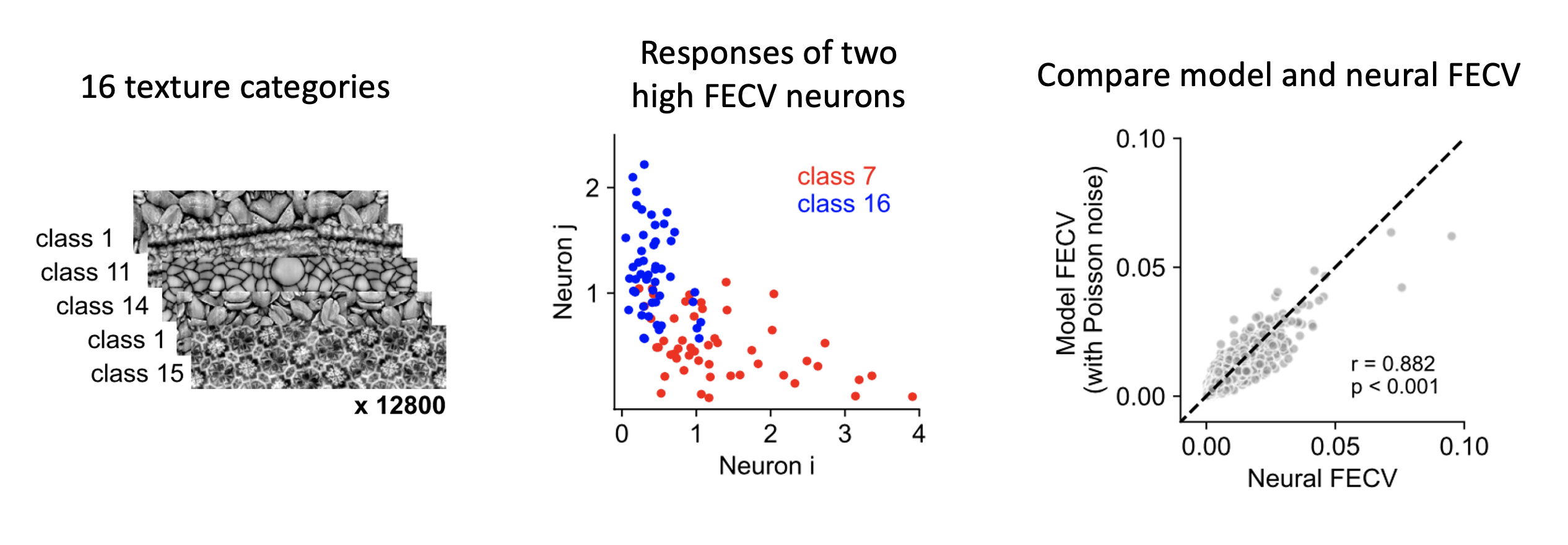
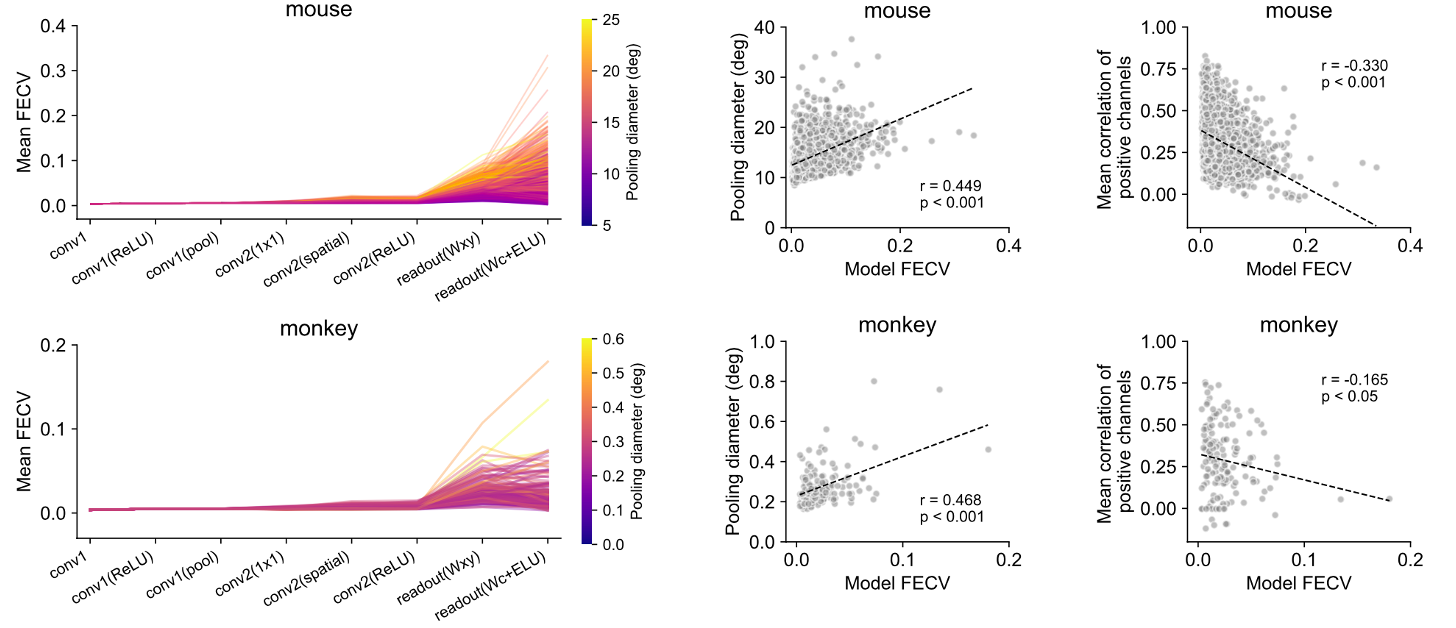
- We found that instead of gradually increasing, the invariance primarily emerges at the readout stage and is influenced by both pooling size and input channel similarity.
- With these minimodels, we can also visualize the high and low FECV neurons in mouse and monkey V1.

- In summary, we found single-neuron minimodels are just as powerful as larger ones! It offers an accurate and interpretable approach to studying visual computation across different species and experimental contexts. 🐭🐒
Huge thanks to Janelia! Thanks to the GENIE project, the Vivarium staff, Sarah Lindo and Sal DiLisio for surgery, Jon Arnold for designing headbars and coverslips, Dan Flickinger for microscopy, and Jon Arnold and Tobias Goulet for engineering support.
Powered by Quarto. © Marius Pachitariu & Carsen Stringer lab, 2026.